今回は、基本的なデータ構造の一つであるスタックとキューを解説します。
スタック(Stack)
スタックとは
スタックはLIFO(Last In First Out)とも呼ばれるデータ構造です。プッシュダウンリストとも呼ばれます。
以下の図のように、一番最後に挿入した要素がデータを取り出す際に一番最初に出てくるようなデータ構造です。
一時的にデータを取り出したい時に有効なデータ構造で、関数呼び出し時のデータ退避のため、逆ポーランド記法の計算のためなどに利用されています。
スタックは、データを追加する操作をプッシュ(push)、データを取り出す操作をポップ(pop)と言います。
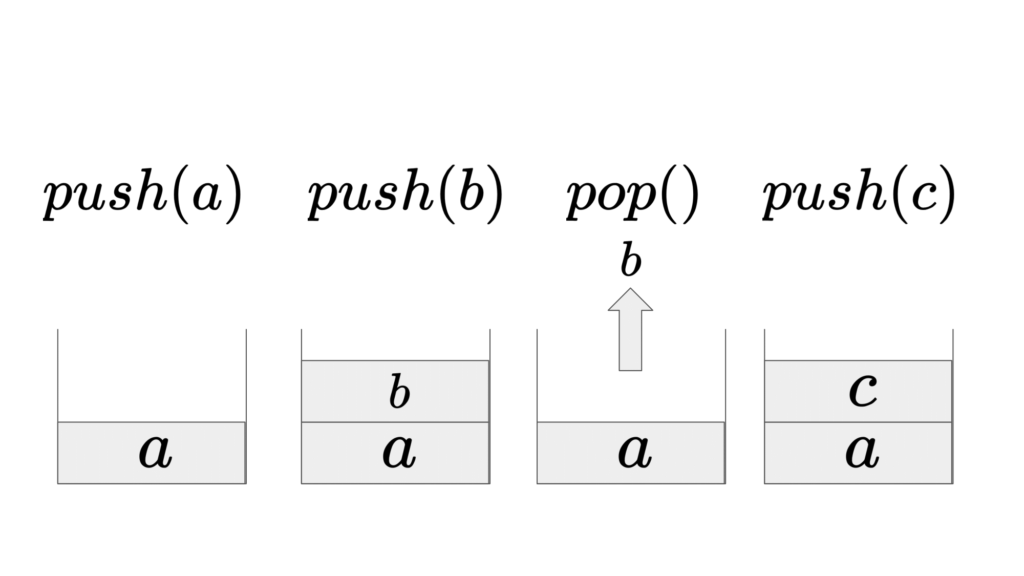
スタックの実現方法
スタックは、前回記事で紹介した連結リストで実現できます。
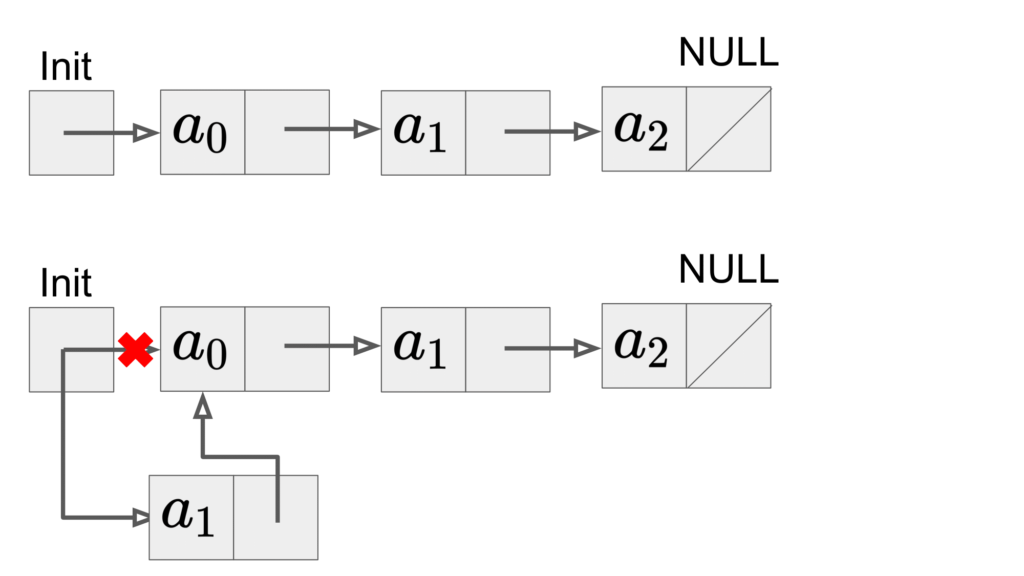
プッシュとポップは常に連結リストの先頭要素InitでInsert, Delete操作を行うことで実装できます。
プッシュ操作は以下の図のように、Initからの要素を新しく追加する要素に変更し、追加した要素の次の要素を元々先頭の要素だったところに変更します。
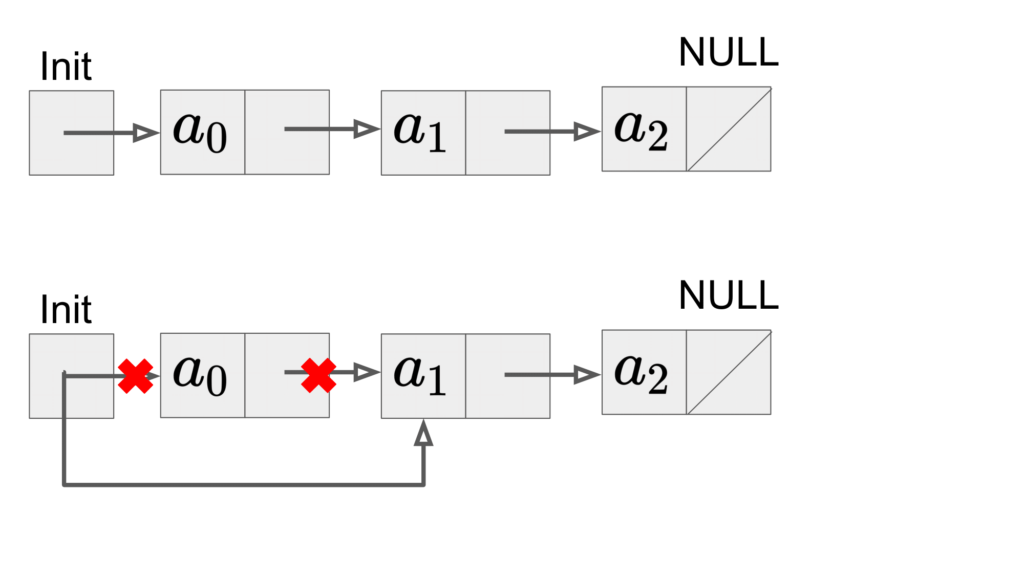
一方で、ポップはInitからの要素\(a_0\)を取り出した後削除し、取り出した要素\(a_0\)の次の要素\(a_1\)をInitからの要素に変更することで実現できます。
キュー(Queue)
キューには
キューはFIFO(First In First Out)とも呼ばれるデータ構造です。
以下の図のように、スタックとは対照的に一番最初に挿入したデータが一番最後に取り出されるようなデータ構造です。待ち行列とも呼ばれたりします。
キューでは、データの挿入操作をエンキュー(Enqueue)、データを取り出す操作をデキュー(Dequeue)と呼びます。
キューは、到着した順番に処理したい場合に有効で、ジョブのスケジューリングなどでよく利用されます。
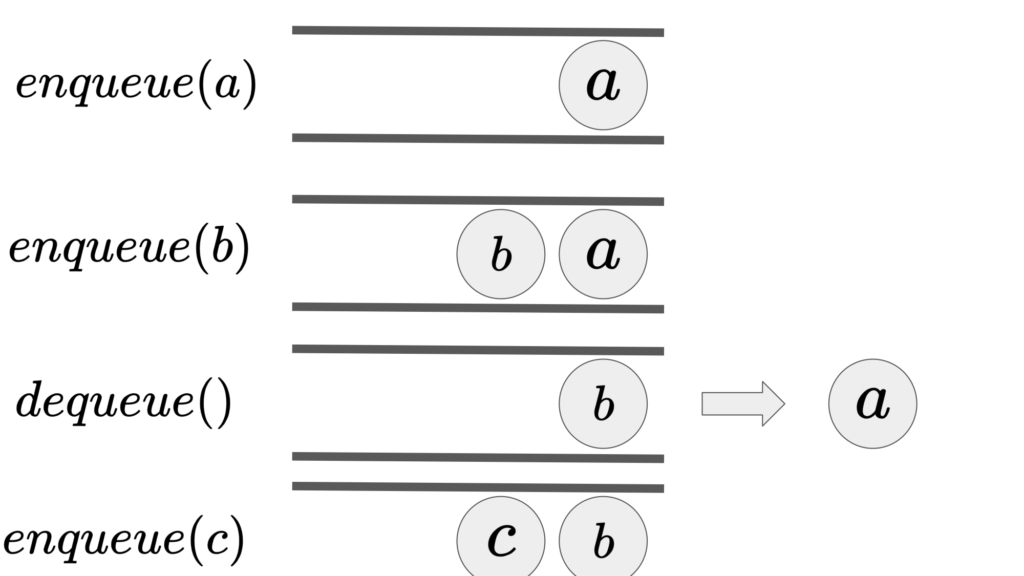
キューの実現方法
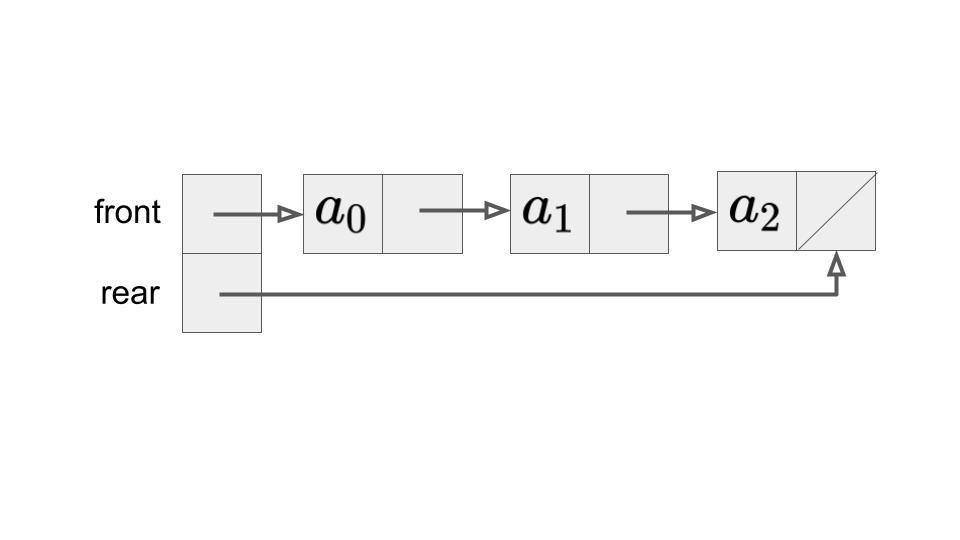
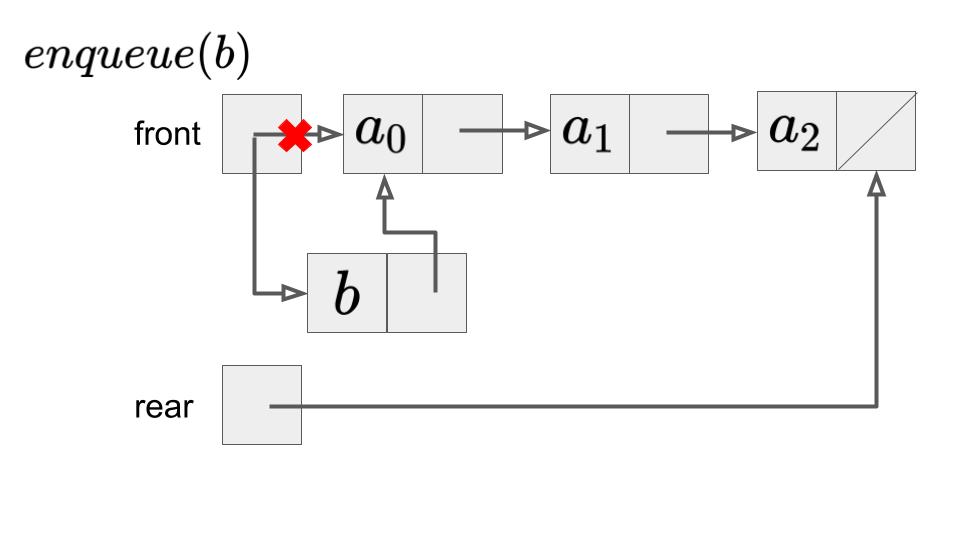
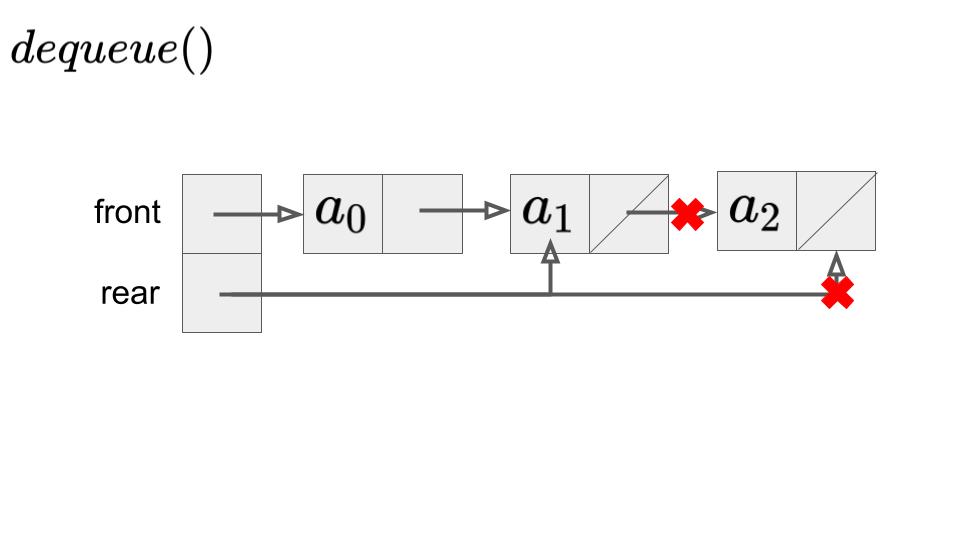
キューもスタックと同様に連結リストで実現することができます。普通の連結リストと異なるのは、先頭要素を表すfrontの他に、最後の要素を示すrearのポインタを持つことです。
キューへのデータの挿入enqueueはfront部分で行うことで実行できます。一方で、データの取り出しdequeueは、rear部分で行うことで実行できます。
まとめ
今回は、基本的なデータ構造の一つであるスタックとキューを解説しました。
スタックとキューはどちらとも線形リストを活用することで実装できることを解説しました。
コメント