API Reference
parameters:
| パラメータ名 | 型 |
|---|---|
a | array_like(N,) 1 次元入力配列 |
v | (M,) array_like 1 次元入力配列 |
mode | {‘full’, ‘same’, ‘valid’}, optional ‘full’: デフォルト値 これは、各重なり点における畳み込みを(N+M-1,)の出力形状で返します。畳み込みの終点では、信号が完全に重なることはなく、境界効果が見られる場合があります。 ‘same’:長さmax(M, N)の出力を返します。境界効果は依然として表示されます。 ‘valid’: max(M, N) – min(M, N) + 1 の出力を返します。畳み込み積は、信号が完全に重なり合う点に対してのみ得られます。信号境界外の値は影響しません。 |
returns:
out: ndarray a と v の離散線形畳み込み
modeについて
numpy.convolveでは、modeが3つ用意されています。これらは、端(境界)のデータをどう扱いたいかによって、modeを変更します。
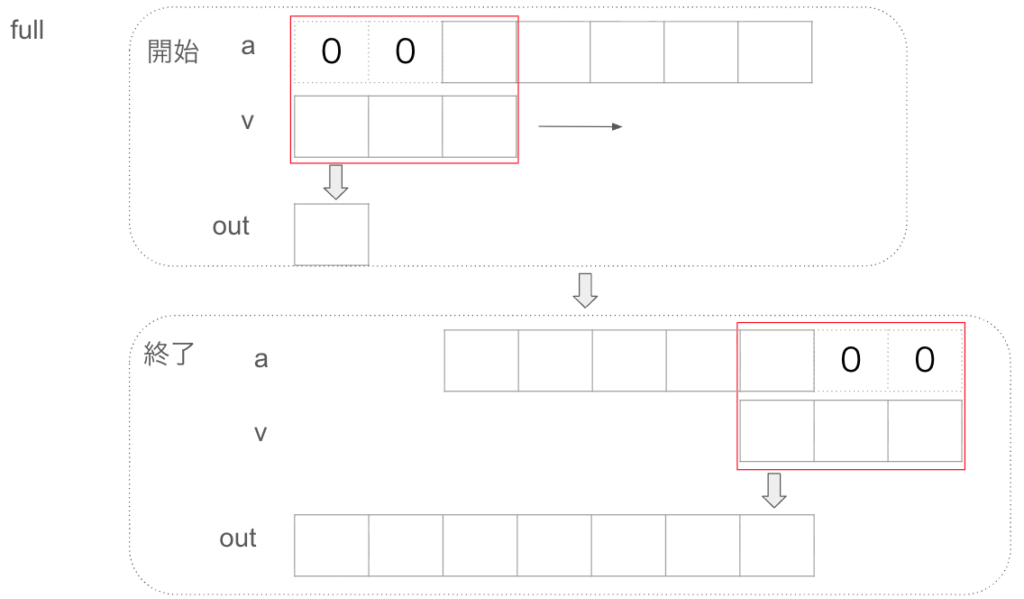
full
数学的な定義そのもので、単純に畳み込みをするというとこのfullを指します。入力データをa, フィルタをvとすると以下の図のように、2つの配列が1つでも重なり合った部分は計算します。少し掠った状態から、完全に重なって、また離れていくまでの全ての過程を出力します。
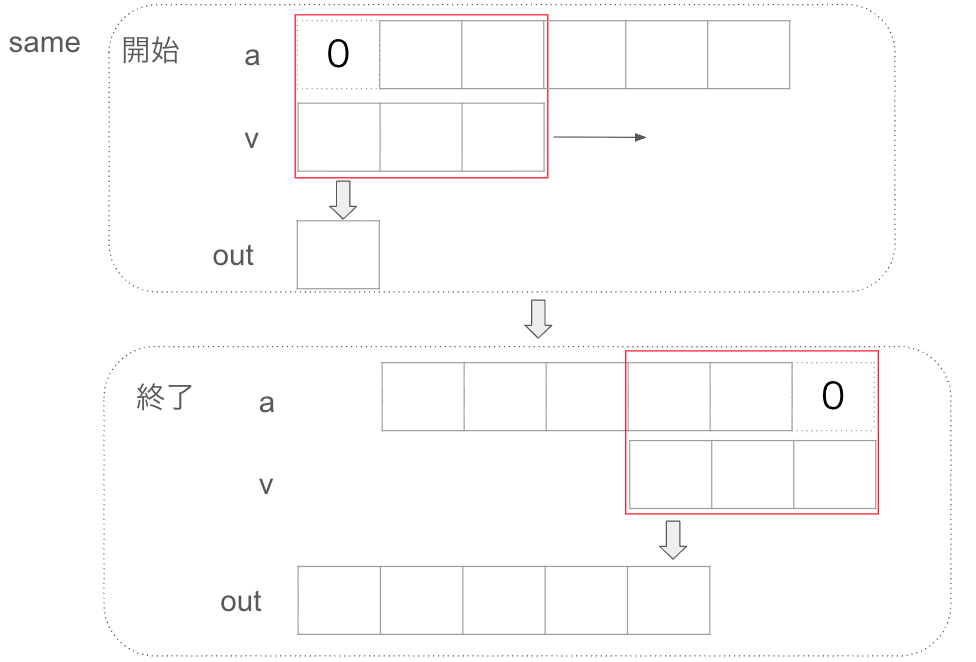
same
fullの結果の中心部分を切り取り、入力aと同じ長さになるように調整します。
入力と出力の時間的なずれをなく、重ね合わせたい時に使用します。例えば、センサデータの移動平均を計算して、元のグラフの上に重ねて描画したいとします。このような時に、出力サイズが変わってしまうと、グラフを書くときに移動平均結果との照らし合わせがしにくくなります。sameであれば、入力データと出力データが変わることがないので確認がしやすいです。
sameの場合は、データ数によって振る舞いが変わるので、注意が必要です。
入力信号をa, フィルタをvとしたとします。
sameは「入力信号1個」につき、「結果が1個」返ってくるということを意識するとわかりやすいかもしれません。実際の動きとしては、以下の図のようにフィルタの中心を入力データの一つ一つ順番に合わせていくようなイメージです。
フィルタ長が奇数の場合は真ん中と入力データの左端を合わせるように開始されます。フィルタの真ん中が入力データの右端まで到達するまで処理を行います。
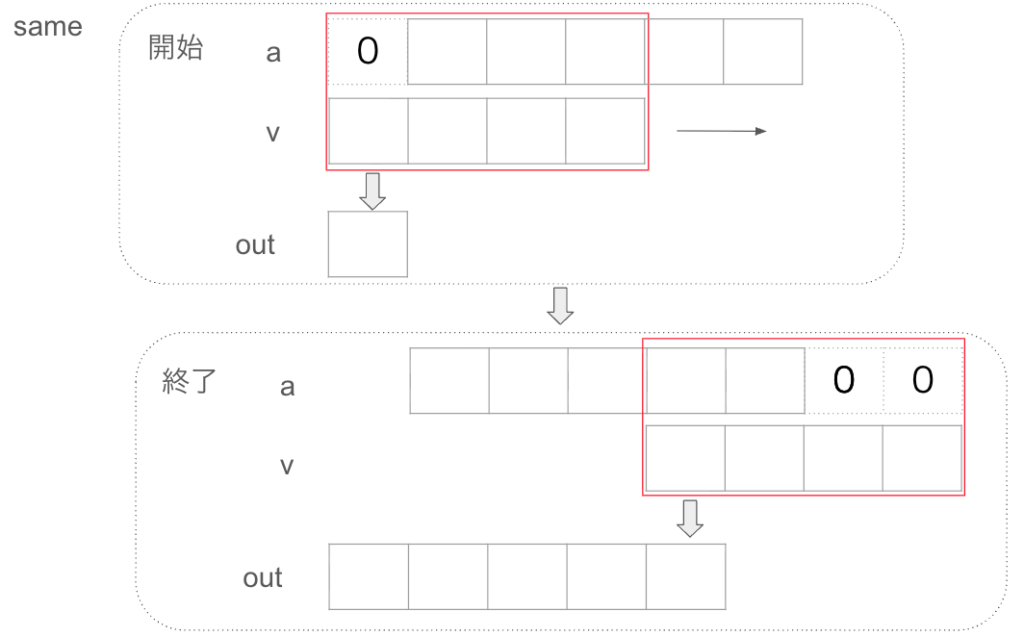
一方で、フィルタ長が偶数の場合は、ピーク位置がずれます。これは真ん中という概念が偶数の場合はないからです。そのため、numpyでは左側を真ん中と定義します。あとは同じように動作します。
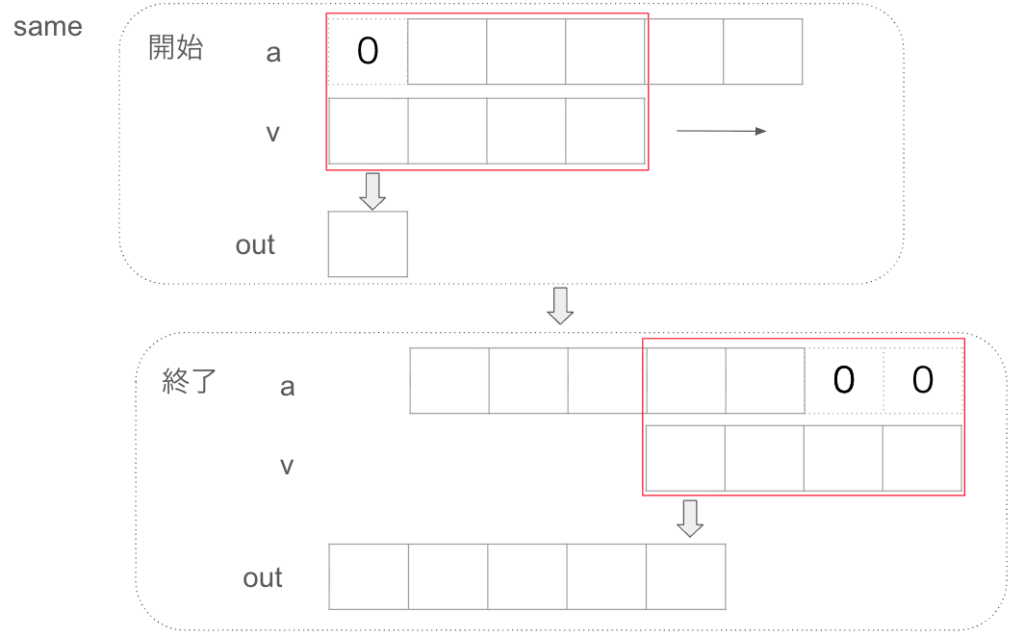
valid
厳密な解析や、機械学習のためのモードです。架空のデータ(ゼロパッディング)を使いたくない場合に使用します。full, sameは未定義な部分(端のデータ)については、0と仮定して埋めています。しかし、実際の状況ではデータがない=0とはならないはずです。validは、このような不確かな計算結果を一切排除し、信頼できるデータのみ残します。
まとめ
本記事では、numpy.convolveの動作について解説しました。modeごとの振る舞いを解説しました。

コメント