本記事では、scikit-learnに含まれているデータセットは何があるのか、サンプルデータの使い方について解説します。
目次
サンプルデータの種類
scikit-learnにはさまざまなデータセットが提供されており、簡単にsickit-learnのモデルに流すことができるため、sickit-learnの機械学習アルゴリズムの動作を簡易的に知りたい場合、各手法の比較等に便利です。提供しているデータセットは大きく2種類に分かれます。
それは、Toy DatasetsとReal World Datasetsの2つです。
Toy Datasetsはscikit-learn自体に内包されているため、ダウンロード不要な小さいデータセットとなっています。Real World Datasetsはダウンロードすることが必要で、サイズの大きなデータセットになっています。
Toy Datasets
Toy Datasetsの特徴を下記にまとめました。
| データセット名 | 詳細 | データ数 | 次元数(特徴量+予測対象) | 用途 |
| boston | ボストンの住宅価格(非推奨) | 506 | 13+1 | 回帰 |
| diabetes | 糖尿病の診断データ | 442 | 10+1 | 回帰 |
| linnerud | 生理学的特徴と運動能力の関係性 | 20 | 3+3 | 回帰 |
| iris | アヤメの計測データ | 150 | 4+1 | 分類 |
| digits | 数字の手書き文字 | 1797 | 64 | 分類 |
| wine | ワインの成分 | 178 | 13 | 分類 |
| breast_cancer | 乳がんの診断データ | 569 | 30 | 分類 |
Real World Datasets
Real World Datasetsの特徴を下記の表にまとめました。
| データセット名 | 詳細 | データ数 | カラム数 | 用途 |
| california_housing | カリフォルニアの住宅価格 | 20640 | 8 | 回帰 |
| olivetti_faces | 顔画像 | 400 | 4096 | 分類 |
| 20newsgroups | トピック別のニュース記事 | 18846 | 1 | 分類 |
| 20newsgroups_vectorized | トピック別のニュース記事(特徴抽出済み) | 150 | 4 | 分類 |
| rcv1 | カテゴリ別のニュース | 804414 | 47236 | 分類 |
| lfw_people | 有名人の顔写真 | 13323 | 5828 | 分類 |
| lfw_pairs | 有名人の顔写真(ペア) | 178 | 13 | 分類 |
| covtype | 木の種類 | 581012 | 54 | 分類 |
| kddcup99 | ネットワークの侵入検知 | 4898431 | 41 | 分類 |
Toy Datasets の使い方
各データセットをpandasで扱いたい場合は変換が必要です。データセットはload_データセット名で取得可能です。引数として、as_frameにTrueを渡すと、DataFrameとして簡単に取り出すことができます。ただし、bostonデータセットのみ将来のバージョンで削除予定のため、この方法は使うことができません。
boston データセット(非推奨)
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
boston_df = pd.DataFrame(boston["data"], columns=boston["feature_names"])
boston_df["target"] = boston["target"]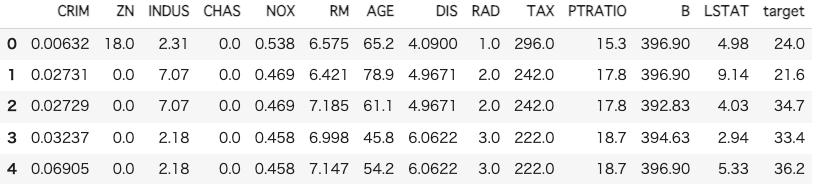
diabetes データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
diabetes_df = pd.DataFrame(diabetes["data"], columns=diabetes["feature_names"])
diabetes_df["target"] = diabetes["target"]scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_diabetes
diabetes_df = load_diabetes(as_frame=True).frame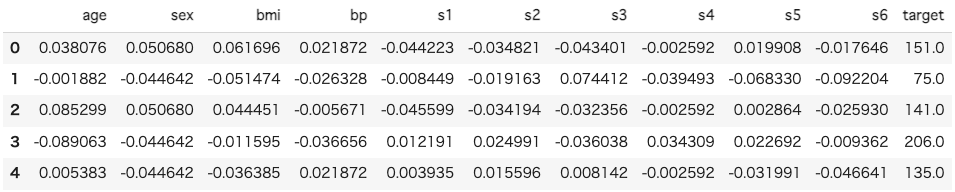
linnerud データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_linnerud
linnerud = load_linnerud()
linnerud_feature_df = pd.DataFrame(linnerud["data"], columns=linnerud["feature_names"])
linnerud_target_df = pd.DataFrame(linnerud["target"], columns=linnerud["target_names"])
linnerud_df = pd.concat([linnerud_feature_df, linnerud_target_df], axis=1)scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_linnerud
linnerud_df = load_linnerud(as_frame=True).frame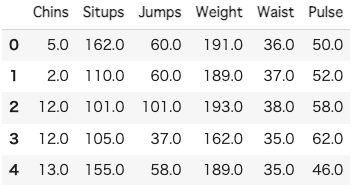
iris データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame(iris["data"], columns=iris["feature_names"])
iris_df["target"] = iris["target"]scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris(as_frame=True).frame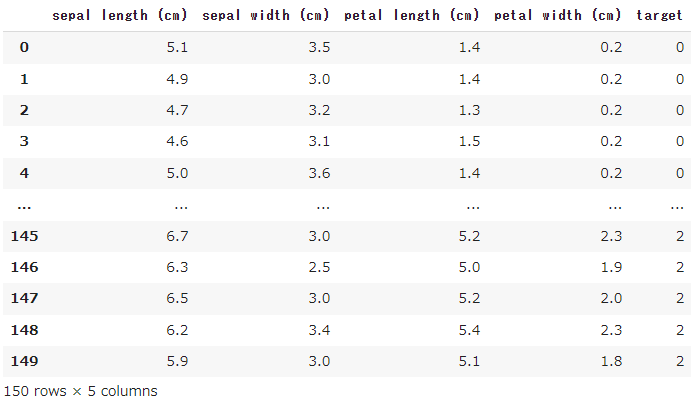
digits データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_digits
digits = load_digits()
digits_df = pd.DataFrame(digits["data"], columns=digits["feature_names"])
digits_df["target"] = digits_df["target"]
#images
digits_images = digits["images"]
digits.shapescikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_digits
digits_df = load_digits(as_frame=True).frame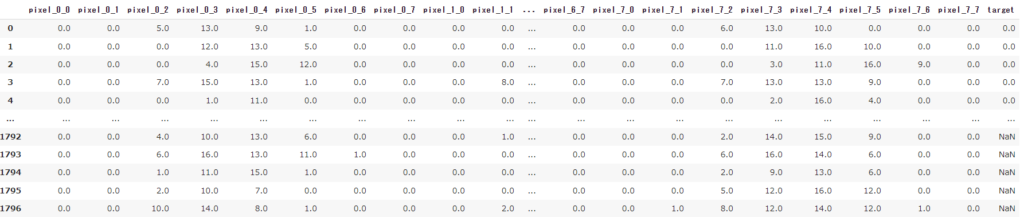
wine データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_wine
wine = load_wine()
wine_df = pd.DataFrame(wine["data"], columns=wine["feature_names"])
wine_df["target"] = wine["target"]scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_wine
wine_df = load_wine(as_frame=True).frame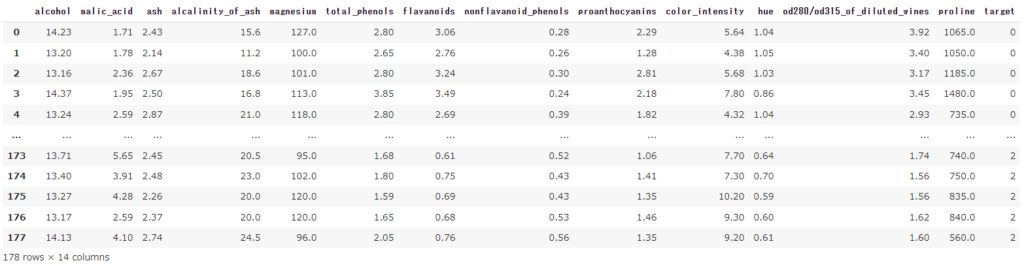
breast_cancer データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
breast_cancer_df = pd.DataFrame(breast_cancer["data"], columns=breast_cancer["feature_names"])
breast_cancer_df["target"] = breast_cancer["target"]scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import load_breast_cancer
breast_cancer_df = load_breast_cancer(as_frame=True).frame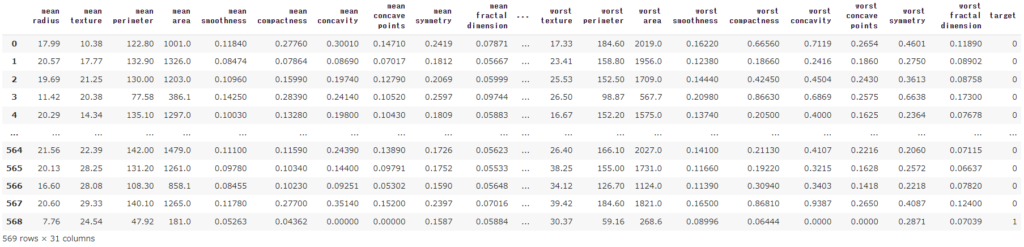
Real World Datasets の使い方
各データセットをpandasで扱いたい場合は変換が必要です。データセットはload_データセット名で取得可能です。ToyDatasetと同様に引数として、as_frameにTrueを渡すと、DataFrameとして簡単に取り出すことができます。
california_housing データセット
scikit-learn 0.22以前
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing()
california_housing_df = pd.DataFrame(california_housing["data"], columns=california_housing["feature_names"])
california_housing_df["target"] = california_housing["target"]scikit-learn 0.22以降
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing_df = fetch_california_housing(as_frame=True).frameolivetti_faces データセット
from sklearn.datasets import fetch_olivetti_faces
olivetti_faces = fetch_olivetti_faces()
images = olivetti_faces["images"]
targets = olivetti_faces["target"]20newsgroups データセット
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
newsgroup20 = fetch_20newsgroups()
num2label = {k: v for k, v in enumerate(newsgroup20.target_names)}
newsgroup20_df = pd.DataFrame(newsgroup20["data"], columns=["text"])
newsgroup20_df["target"] = newsgroup20["target"]
newsgroup20_df["target_names"] = newsgroup20_df["target"].apply(lambda x : num2label[x])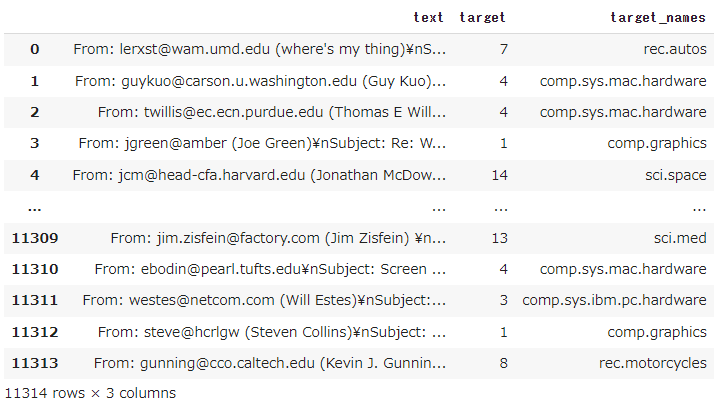
20newsgroups_vectorized データセット
import pandas as pd
from sklearn.datasets import fetch_20newsgroups_vectorized
newsgroup20_vectorized = fetch_20newsgroups_vectorized()
# 130107次元のデータ sparse matrixとして格納されている
data = newsgroup20_vectorized.data
target = newsgroup20_vectorized.targetrcv1 データセット
import pandas as pd
from sklearn.datasets import fetch_rcv1
rcv1 = fetch_rcv1()
data = rcv1.data # ベクトル化済み 47236次元のデータ sparse matrixtとして格納されている
target = rcv1.targetlfw_people データセット
from sklearn.datasets import fetch_lfw_people
lfw_people = fetch_lfw_people()
images = lfw_people.images
targets = lfw_people.targetlfw_pairs データセット
from sklearn.datasets import fetch_lfw_pairs
lfw_pairs = fetch_lfw_pairs()
image_pairs = lfw_pairs.pairs
targets = lfw_pairs.targetcovtype データセット
from sklearn.datasets import fetch_covtype
covtype = fetch_covtype()
covtype_df = pd.DataFrame(covtype["data"], columns=covtype["feature_names"])
covtype_df["target"] = covtype["target"]kddcup99 データセット
from sklearn.datasets import fetch_kddcup99
kddcup99 = fetch_kddcup99()
kddcup99_df = pd.DataFrame(kddcup99["data"], columns=kddcup99["feature_names"])
kddcup99_df["target"] = kddcup99["target"]まとめ
本記事では、scikit learnに含まれているデータセットについて解説しました。

コメント