ランダムフォレストは、決定木を弱学習器とするアルゴリズム分類問題でも回帰問題でも適用可能です。決定木では、過学習に陥りやすいという課題があるため、ランダムフォレストではその決定木を複数個作成してアンサンブルすることで、この課題に対応しています。決定木を作る時には、似たような決定木を作成しても精度が上がらないため、それぞれの木を異なるデータで作成することで、多様性を保つことで過学習に対応します。分類問題であれば、多数決をとり、回帰問題では平均値をとるなどの処理を行います。
scikit-learnのランダムフォレストにおける重要なパラメータとして、n_estimatorsがありますが、これは使用する決定木の数を選択するパラメータで、木の数が多すぎても精度が上がらず、少なすぎても過学習を起こしてしまうため、うまく調整する必要があります。
目次
RandomForestClassifier, RandomForestRegressorの使い方
【RandomForestClassifier()、またはのRandomForestRegressor()の引数】
- n_estimators:決定木の個数を指定
- criterion:決定木のデータ分割の指標((デフォルトはgini)
- max_depth: 決定木の深さの最大値を指定
- n_jobs: 計算に使うジョブの数
- random_state: 乱数
- verbose: モデル構築の過程のメッセージを出すかどうか(デフォルトは0)
また、作成したインスタンスへの基本的なメソッドは以下となります。【クラスのメソッド】
- fit(X, y[, sample_weight]):学習の実行
- get_params([deep]):学習の際に用いたパラメータの取得
- predict(X): 予測の実行
- score(X, y[, sample_weight]): 決定係数の算出
- feature_importances_: 説明変数の特徴量重要度
- set_params(**params): パラメータの設定の確認
scikit-learnの機械学習モデルの中でも、ランダムフォレスト独自のものが存在しています。ランダムフォレストでは学習した際にどの特徴量が効いたかを定量的に算出することが可能とする、feature_importance_というメソッドを持っています。これを使用すると、各特徴量がどの程度性能に寄与しているかがわかります。
分類
ライブラリのインポート
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_scoreデータセットの準備
wine_df = load_wine(as_frame=True).frame
X = wine_df.drop("target", axis=1).values
y = wine_df["target"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)モデルの構築と学習
model = RandomForestClassifier(
n_estimators=100,
criterion="gini",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0,
max_features="sqrt",
max_leaf_nodes=None,
min_impurity_decrease=0,
bootstrap=True,
oob_score=False,
n_jobs=4,
random_state=42,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0,
max_samples=None,
)
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)評価と特徴量の重要度の可視化
print("accuracy train data: ", accuracy_score(y_train, y_train_pred))
print("accuracy test data: ", accuracy_score(y_test, y_test_pred))
print("f1 train data: ", f1_score(y_train, y_train_pred, average="micro"))
print("f1 test data: ", f1_score(y_test, y_test_pred, average="micro"))
feature_importance = pd.DataFrame({'feature':wine_df.drop("target", axis=1).columns,'importances':model.feature_importances_}).sort_values(by="importances", ascending=False)
sns.barplot(x="importances", y="feature", data=feature_importance)
plt.show()accuracy train data: 1.0
accuracy test data: 0.9814814814814815
f1 train data: 1.0
f1 test data: 0.9814814814814815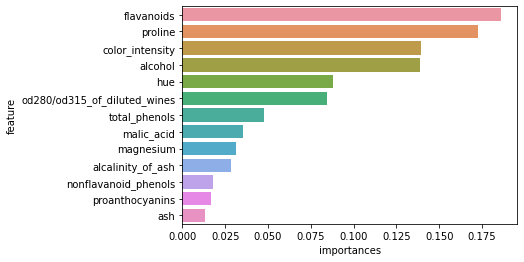
回帰
ライブラリのインポート
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error
import matplotlib.pyplot as pltデータセットの準備
diabetes_df = load_diabetes(as_frame=True).frame
X = diabetes_df[['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']].values
y = diabetes_df["target"].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42,
)モデルの構築と学習
model = RandomForestRegressor(
n_estimators=100,
criterion="squared_error",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0,
max_features=1.0,
max_leaf_nodes=None,
min_impurity_decrease=0,
bootstrap=True,
oob_score=False,
n_jobs=4,
random_state=42,
verbose=0,
warm_start=False,
ccp_alpha=0,
max_samples=None
)
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)評価と特徴量の重要度の可視化
# 残差プロット
figure, axes = plt.subplots(1, 2, figsize=(20,5))
axes[0].scatter(y_train_pred, y_train_pred - y_train)
axes[0].hlines(y=0, xmin=np.min(y_train_pred), xmax=np.max(y_train_pred))
axes[1].scatter(y_test_pred, y_test_pred - y_test)
axes[1].hlines(y=0, xmin=np.min(y_test_pred), xmax=np.max(y_test_pred))
# MAE
print("MAE train data: ", mean_absolute_error(y_train, y_train_pred))
print("MAE test data: ", mean_absolute_error(y_test, y_test_pred))
# 特徴量の可視化
feature_importance = pd.DataFrame({'feature':diabetes_df.drop("target", axis=1).columns,'importances':model.feature_importances_}).sort_values(by="importances", ascending=False)
sns.barplot(x="importances", y="feature", data=feature_importance)
plt.show()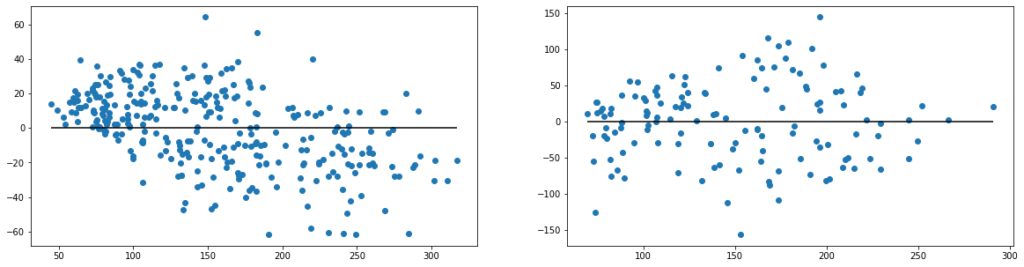
MAE train data: 18.252103559870548
MAE train data: 42.779548872180456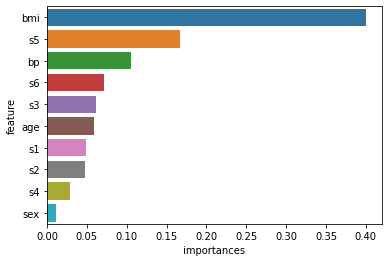
まとめ
本記事では、ランダムフォレストを使用した分類、回帰のモデルの学習および推論方法を紹介しました。ランダムフォレストでは、各特徴量の重要度が可視化することができ、それらの方法についても紹介しました。

コメント