教師なし学習の一つで、クラスタリング手法の一つです。非階層クラスター分析の一つに含まれます。
k-means法のフロー
- クラスタ数を決定し、ランダムに初期値を決定する
- 割り振ったデータをもとに各クラスタのクラスを推定
- 推定したクラスごとの重心を計算する
- 1~3を繰り返す
目次
KMeansの使い方
【KMeans()の引数】
- n_clusters: クラスタ数(デフォルトは8)
- max_iter:繰り返し回数の最大(デフォルトは300)
- n_init: 初期値選択において、異なる乱数のシードで初期の重心を選ぶ処理の実行回数(デフォルトは10)
- init: 初期化の方法(‘k-means++’, ‘random’)(デフォルトは’k-means++’)
- tol:収束判定に用いる許容可能誤差(デフォルトは0.0001)
- random_state: 乱数
- copy_x: メモリ内でデータを複製してから実行するかどうか(デフォルトはTrue)
- n_jobs: 並列処理する場合の多重度(デフォルトは1)
【クラスのメソッド】
- fit(X):クラスタリングの計算の実行
- fit_predict(X):各サンプルに対する、クラスタ番号を求める
- fit_transform(X): クラスタリングの計算を行い、Xを分析に用いた距離空間に変換して返す
- predict(X): Xのサンプルが属しているクラスタ番号を返す
- inertia_: 各クラスター内の二乗誤差を返す
クラスタリングの実行
ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeansデータセットの準備
X, y = make_blobs(
n_samples=100,
centers=4,
cluster_std=1.0,
shuffle=True,
random_state=42)
x0 = X[:, 0]
x1 = X[:, 1]
plt.scatter(x0, x1)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()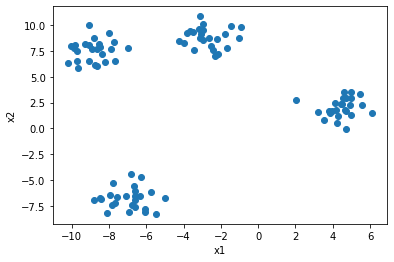
クラスタリング
model = KMeans(n_clusters=4, random_state=0, init='random')
model.fit(X)
clusters = model.predict(X)
cluster_centers = model.cluster_centers_クラスタリング結果の可視化
plt.scatter(x0[clusters==0], x1[clusters==0], label="cluster1")
plt.scatter(x0[clusters==1], x1[clusters==1], label="cluster2")
plt.scatter(x0[clusters==2], x1[clusters==2], label="cluster3")
plt.scatter(x0[clusters==3], x1[clusters==3], label="cluster4")
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker="*", s=200)
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend()
plt.show()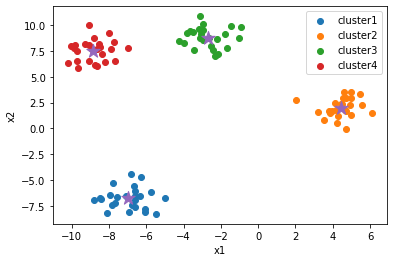
エルボー法による最適クラスタ数の推定
distortions = []
for i in range(1, 11):
model = KMeans(n_clusters=i)
model.fit(X)
distortions.append(model.inertia_)
# グラフのプロット
plt.plot(range(1, 11), distortions, marker="o")
plt.xticks(np.arange(1, 11, 1))
plt.xlabel("Number_of_clusters")
plt.ylabel("Distortion")
plt.show()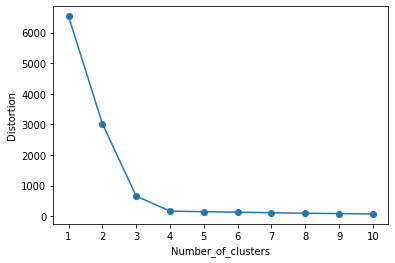
まとめ
本記事では、k-means法を使用してクラスタリングを実行する方法を紹介しました。また、エルボー法で最適なクラスタ数を推定する手順も紹介しました。

コメント